Malachowsky Family Rising Star Assistant Professor, University of Florida
Research Projects
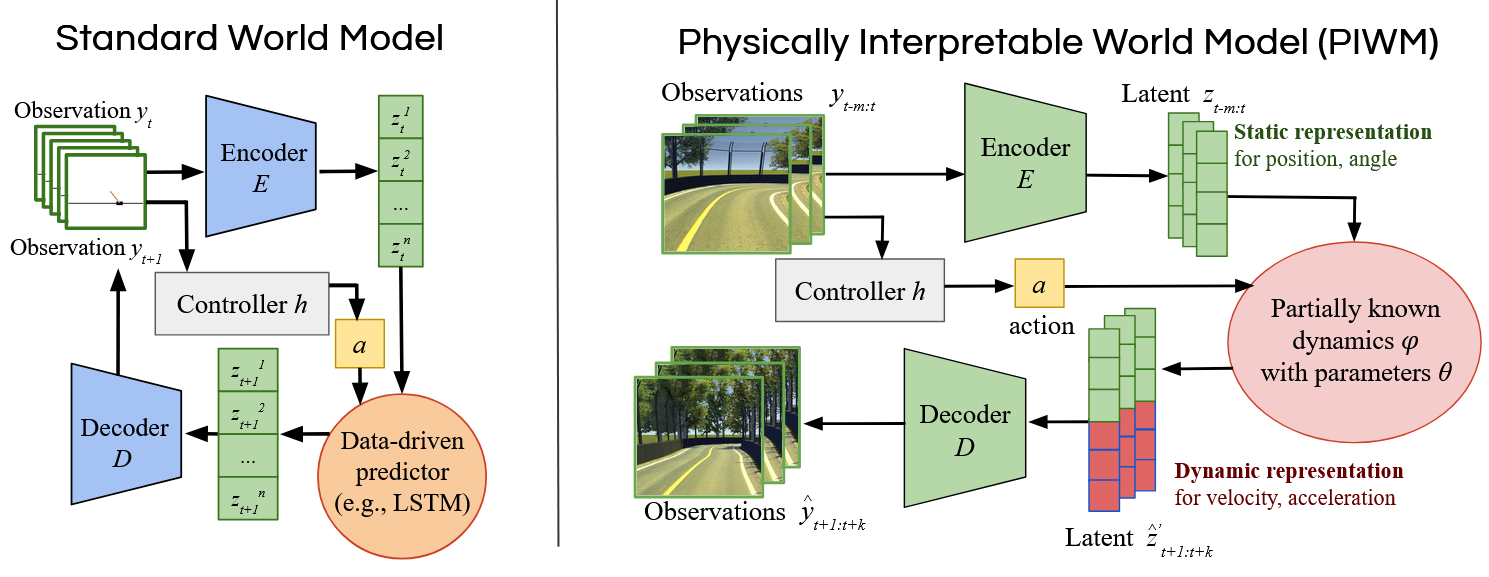
Physically Interpretable World Models
Serving the purposes of reinforcement learning, control, and adaptation, world models predict future observations from high-dimensional sensor data (e.g., camera images). Their learned latent representations often function as black boxes without a clear connection to the underlying physical states, which makes it difficult to provide strong guarantees based on such world models. This project develops Physically Interpretable World Models (PIWM), a novel architecture that aligns learned latent representations with real-world physical quantities.
This project addresses a fundamental question: what does it take to make world models physically interpretable? Some preliminary answers:
We discovered four principles that support physical interpretability: (i) latent structuring, (ii) using invariances and equivariances, (iii) using multi-level supervision, and (iv) partitioning the output decoders.
By combining physically interpretable autoencoders with partially known dynamics models, our PIWM architecture enables trajectory prediction that is both accurate and grounded in physical meaning.
We only use weak distributional supervision rather than requiring precise physical state annotations, making it practical for real-world deployment where exact state measurements are rarely available.
Check out our paper and artifacts on the four principles of physically interpretable world models: [Arxiv] [OpenReview] [Github] [Poster] [Slides].
Check out our paper on the latest PIWM architecture: [Arxiv] [Slides].
Check out this overview talk on reliable world models: [Slides]
Calibrated Safety Chance Predictions from Images
In the absence of the notion of a low-dimensional and interpretable dynamical state, online safety prediction is a challenge. In this project, we investigate a configurable family of learning pipelines based on generative world models, which do not require low-dimensional states. To implement these pipelines, we overcome the challenges of learning safety-informed latent representations and missing safety labels under prediction-induced distribution shift. These pipelines come with statistical calibration guarantees on their safety chance predictions based on conformal prediction.
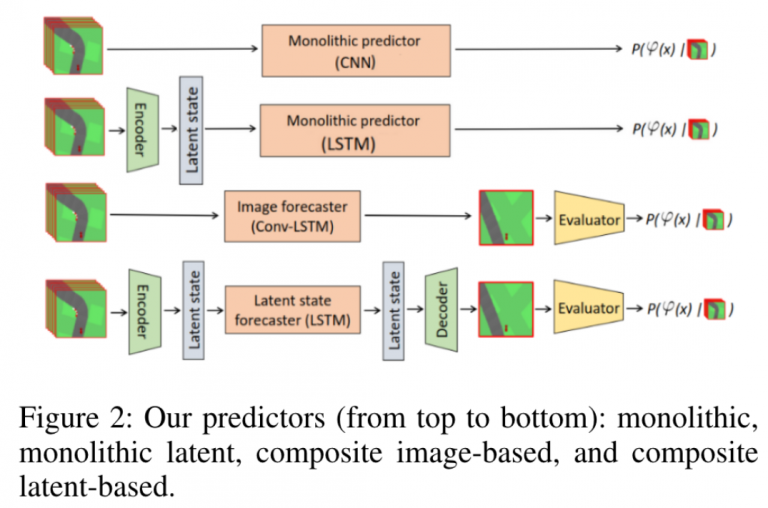
Our safety prediction pipelines are constructed from different architectures (see the image on the right) with the following techniques:
Safety chance predictor that predicts safety directly, or uses an image or latent state forecaster to predict observations, and then a safety evaluator.
Unsupervised domain adapter adjusts the weights of the safety evaluator to mitigate the distribution shift that arises in the forecasted observations.
Conformal calibration combines conformal prediction and confidence calibration together to ensure a statistical guarantee for the predicted interval of safety chances.
To learn more:
Check out this L4DC paper on the latent-space predictors [Arxiv] [Poster]
Foundation models (SAM+GPT) can serve as components of world models to execute zero-shot safety predictions [Arxiv] [Poster]
Related OOD detection using a language-informed multimodal model [Arxiv]
Check out our journal extension with transformer predictors and autonomous car racing [Arxiv].
Check out our physically interpretable world models for better trajectory prediction [Arxiv]
Confident Reachability for High-Dimensional Control/Perception
End-to-end neural network controllers have been extensively used in complex and safety-critical autonomous systems in recent years. In particular, the high-dimensional controllers (HDCs), which process inputs like images and LiDAR, have demonstrated impressive performance. However, due to the high-dimensional nature of the inputs, modern verification techniques cannot be directly applied to these HDCs.
Therefore, to verify the safety of HDC, we propose an end-to-end methodology with the following steps:
Train one or multiple low-dimensional controllers (LDCs) that mimic the performance of the HDC with knowledge distillation.
Calculate two statistical bounds to measure trajectory and control action discrepancy between HDC and LDC by conformal prediction.
Combine reachability analysis on LDC and statistical bounds to provide a safety guarantee for HDC systems.
A similar problem arises with verifying high-dimensional perception. We have developed a methodology to abstract it with statistically valid bounds on the perception error and feed these bounds into closed-loop reachability analysis. The bounds are synthesized by using gradient-free optimization for a loss function over conformal bounds in regions different regions of the state space.
For more information:
For high-dimensional control, read our FM’24 “Bridging Dimensions” paper [Arxiv] [Springer]
Along similar lines, check out our HSCC’25 paper on distributionally robust statistical verification in high state dimensions [Arxiv] [ACM] [Slides].
Repairing Neural Control Policies while Preserving What Works
Learnable control policies have been widely implemented by neural networks, and researchers have developed various neural network repair techniques when these policies do not satisfy a formal specification, such as signal temporal logic (STL). A yet-to-be-addressed challenge is to preserve existing correct policy behaviors during the repair.
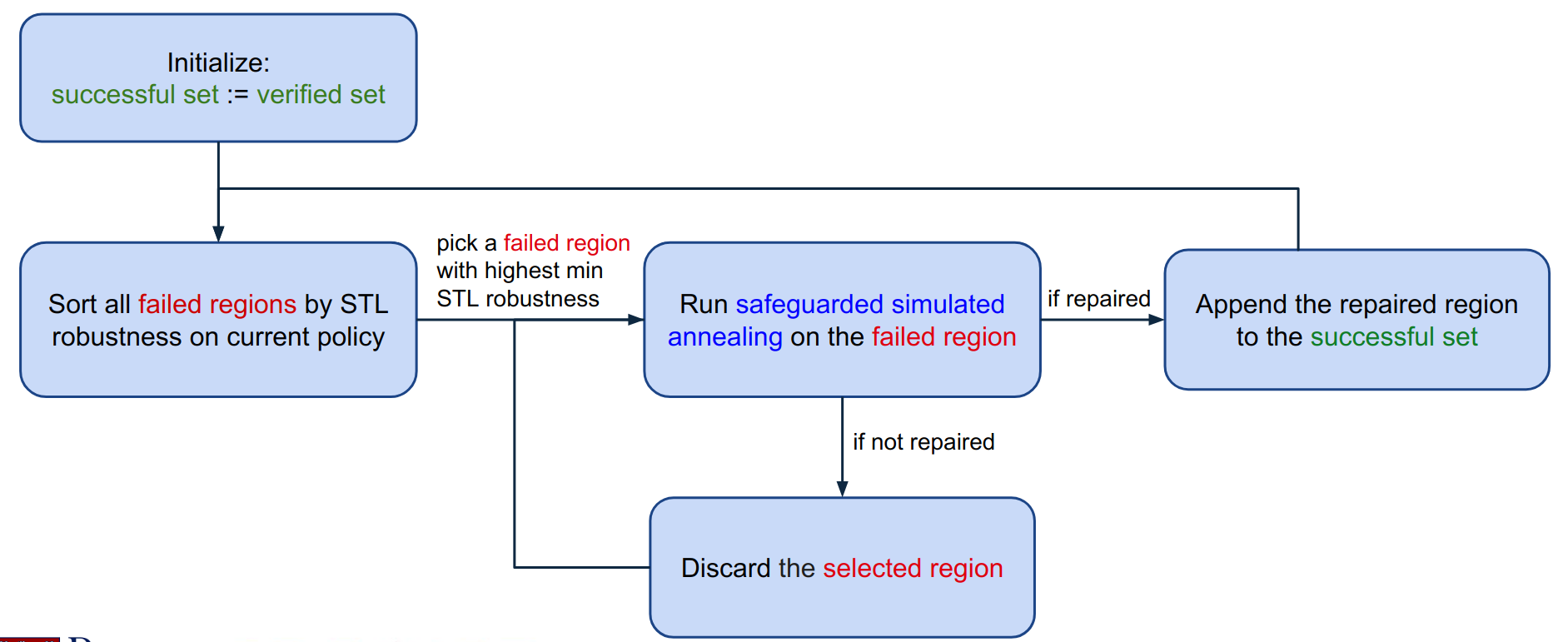
To preserve verified behaviors, we propose an algorithm named Incremental Simulated Annealing Repair(ISAR). This algorithm:
Iteratively selects a small initial state region with an incorrect trajectory sampled.
Repairs this region by safeguarded simulated annealing, while the safeguard is done by a log barrier on verified regions and roll-back mechanism.
Verifies all initial state regions again upon termination.
Our algorithm preserves the verified initial state regions to be still verified after the repair. In our case studies, ISAR maintains the verification results on OpenAI Gym Mountain Car and an unmanned underwater vehicle.
To learn more:
Check out the original paper on ISAR [link] [slides].
Check out the journal extension of ISAR with many repair baselines [link].
Check out a Bayesian extension that speeds up ISAR-I by an order of magnitude [link] [slides].
Read more on a previous method, namely minimally deviating repair, which aims to preserve correctness during neural network policy repair. This method assumes Lipschitz continuity between network parameters and performance metrics, while our method does not [link].
Check out our previous work on causal neural-network repair [link] .
Miscellaneous Past Projects
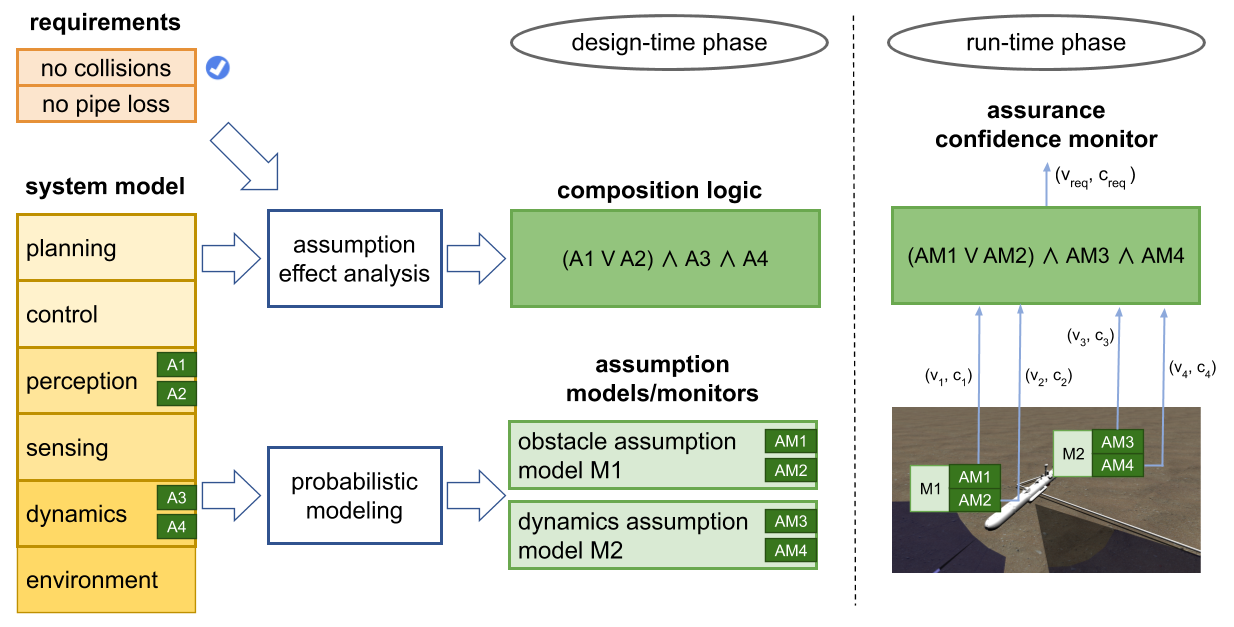
Confidence Monitoring based on Verification of Autonomous Systems
Exhaustive reachability analysis of systems with neural networks promises strong guarantees of safety and performance, but it is computationally feasible only on simplified models. These models may turn out to be invalid at run time due to distribution shift, model inaccuracy, and unexpected noise. To be trustworthy, the system needs to dynamically quantify the extent to which its verification guarantees hold during its execution. Our key insight is that a verified system will uphold its guarantees as long as the assumptions behind its verification are satisfied.
Building on this insight, I led the development of a three-step confidence composition framework:
Verify that the system guarantees a desired property under a propositional formula over some assumptions.
Build, calibrate, and deploy a probabilistic confidence monitor for each assumption.
Compose the outputs of the monitors into a single confidence measure using a function that is informed by the assumptions formula and dependencies between assumptions and monitors.
This framework ensures that the composed confidence is calibrated and conservative with respect to the safety chance, up to a bounded error. In our experiments on a mountain car and an underwater vehicle controlled by neural networks, the composed confidence predicted safety violations and outperformed individual assumption monitors.
Read the more detailed technical paper on the theory and applications of monitoring and composing confidence in verification assumptions.
Read a more recent paper along similar lines on calibrated safety monitoring of probabilistic systems.
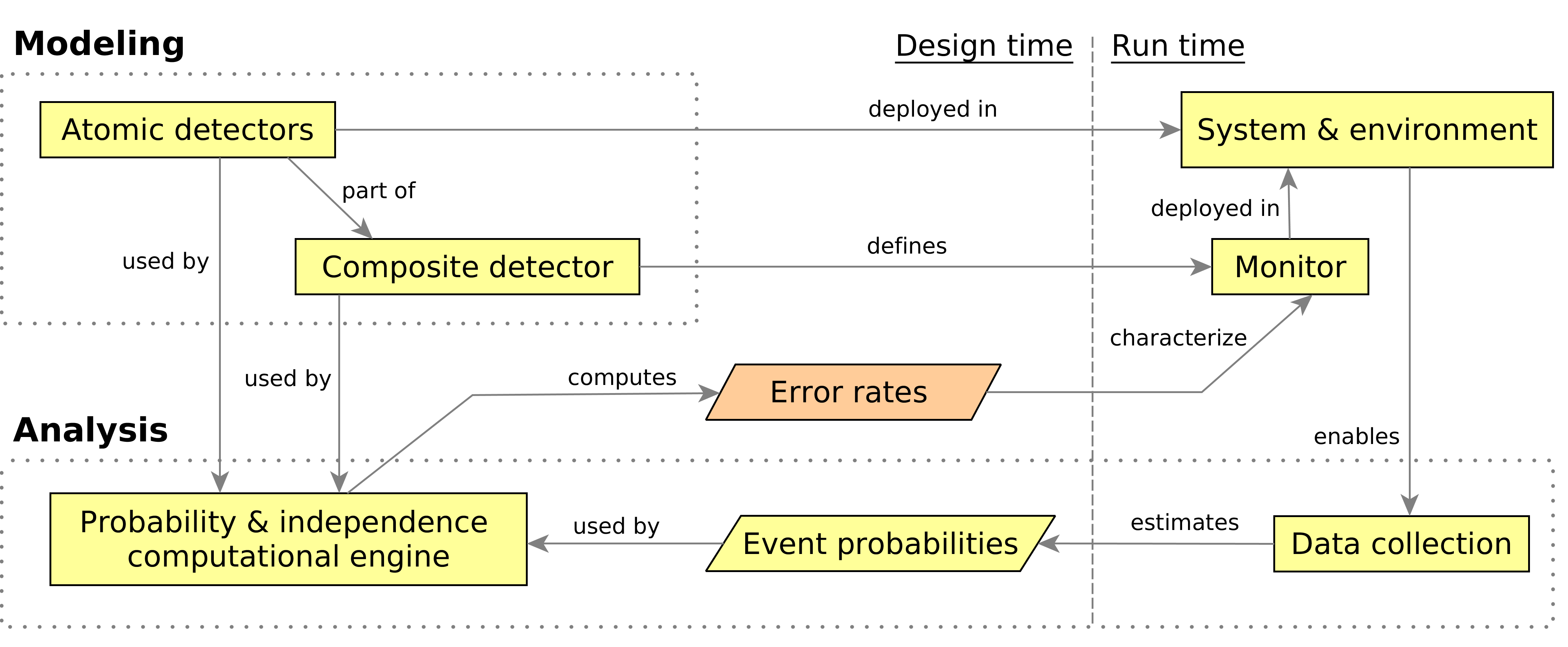
Estimating Detection Rates with Incomplete Information
When machine learning is used in a system’s perception, the downstream components, such as detectors and run-time monitors, often become untrustworthy. It is important to quantify this loss of trust, and I aim to do so through the detection rates of discrete-output detectors and monitors.
Detection rates are usually uncertain because labeled testing data is limited and the monitors use unreliable outputs of learned perception. By analyzing detection rates under these uncertainties, I developed techniques that are promising for broader notions of trustworthiness, such as time-sensitive alarms, continuous confidence, and monitor-driven recovery.
Thus far, I estimated detection rates in two settings:
For safety monitors specified in linear temporal logic (LTL) with noisy inputs, I developed an analytic theory of detector composition. This theory enhanced LTL with the semantics of stochastic three-value detectors. In our case studies, we demonstrated that this framework enables accurate and data-efficient symbolic reasoning about detector rates via logical, algebraic, and independence theories.
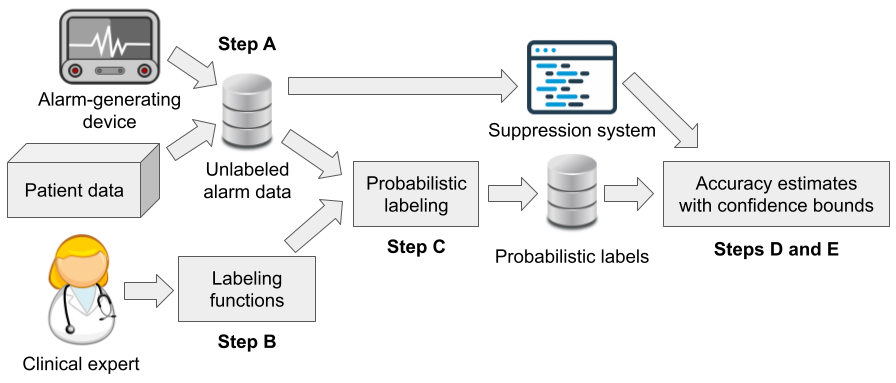
We estimated detection rates of a clinical alarm suppression in the absence of labeled data. Using clinical heuristics as weak labeling functions, we relied on data programming to produce high-confidence labels and infer narrow Probably Approximately Correct (PAC) statistical bounds that contained the true rates with high probability.
In general, the above analysis approaches determine how much monitor outputs can be trusted, which can be represented as run-time confidence and combined with other components.
Learn more:
Check out the compositional analysis of LTL monitors in this video or in this paper.
The work on evaluating alarm classifiers with weak supervision is led by Sydney Pugh and can be found in this and this paper.
Leveraging Domain Knowledge in Trustworthiness Analysis
When analyzing a complex system, engineers often have less-than-certain domain knowledge about the system or its environment. In a data-driven system, this knowledge may not be straightforward to incorporate into trustworthiness analysis, and as a result, the opportunity may be lost.
We investigated two probabilistic ways of exploiting domain knowledge and intuitive heuristics in trustworthiness analysis:
We improved the scalability of probabilistic/statistical model checking for systems with DNN-based perception by removing the safer behaviors from the system’s model. The approximate and partial intuitions about behavior safety were represented with monotonic safety (MoS) heuristics. For example, for an emergency braking system in the Carla simulator, an MoS heuristic is that “it is safer to drive slower”. When correct, using MoS heuristics is provably conservative. In our experiments, MoS led to order-of-magnitude improvements in the run times and data efficiency of model checking, as well as empirical conservatism even when the MoS heuristic is not perfectly accurate.
We helped engineers encode their knowledge about the desired temporal simulation scenarios in a declarative domain-specific language (DSL), which captures the constraints on marginal/joint/conditional probabilities, conditional independence, and temporal relations between categorical simulation variables. Our Probability Specification Tool (PROSPECT) algebraically solves these constraints, guaranteeing to find a unique distribution if it exists. Three case studies showed that our DSL specifications were more succinct than imperative probabilistic programs and avoided sampling mis-specification errors.
Integration of Modeling Methods for Cyber-Physical Systems
Modern cyber-physical systems (CPS), like autonomous drones and self-driving cars, are particularly demanding of rigorous quality assurance because of their impact on our lives. This assurance often relies on diverse modeling methods from a broad range of scientific and engineering fields, from optimization algorithms to mechanical engineering.
Diverse models and analyses are difficult integrate (i.e., use in combination towards a shared goal) due to their complexity and heterogeneity. When they are combined in an ad hoc way, inconsistencies may emerge between models, potentially leading to critical failures in CPS. Even if models are made consistent at some point, uncontrolled changes (both manual and automated) to models may violate that consistency.
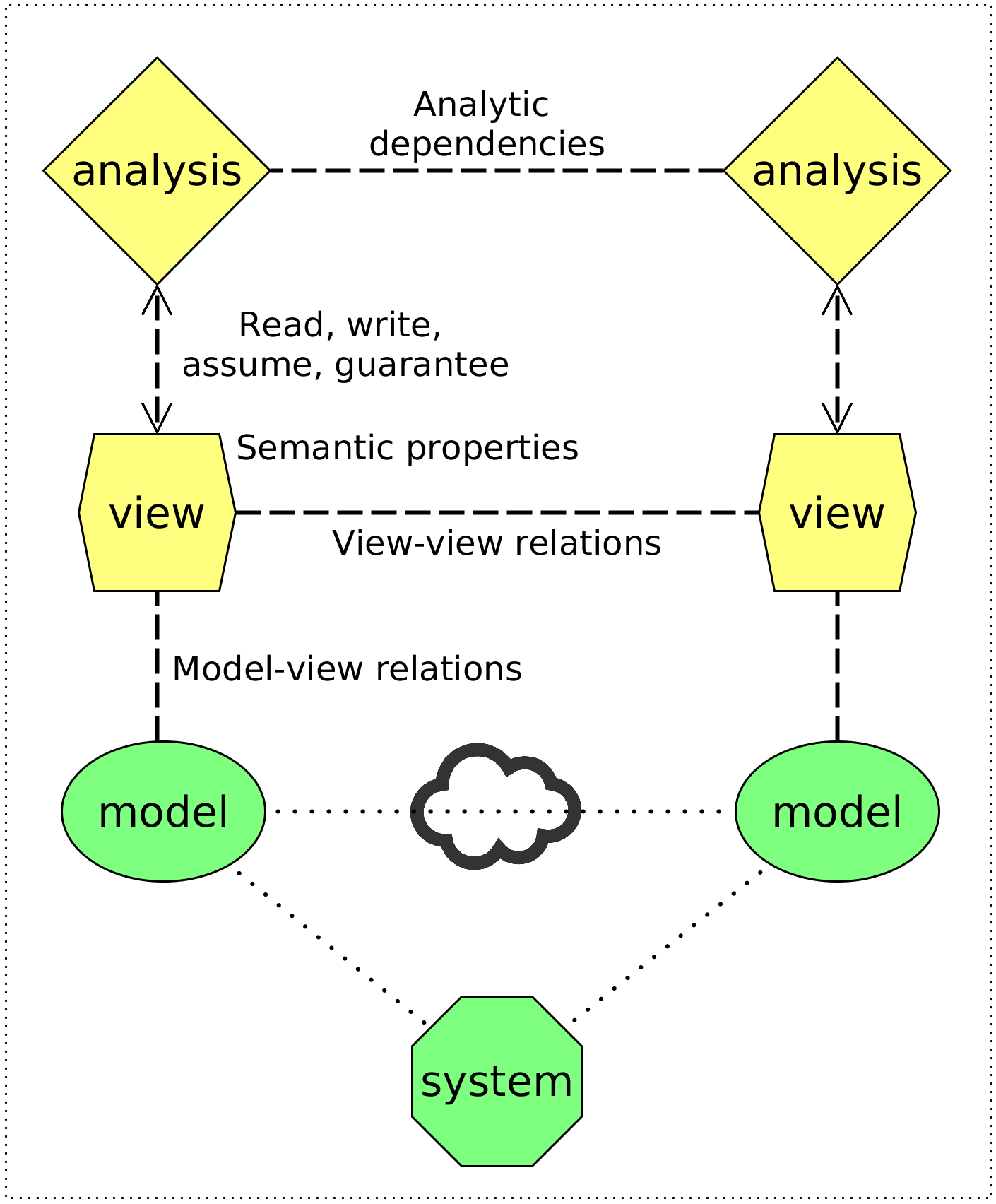
My dissertation develops an augmented architectural approach (see the image) to integration of CPS modeling methods. This approach relies on architectural views (i.e., component-and-connector models annotated with types and properties) to represent and check integration-relevant information from detailed CPS models (e.g., hybrid programs).
The augmented architectural approach relies on three novel integration techniques. First, automated model-view relations preserve the correspondence between models and their respective views using domain-specific model transformations. To prevent inconsistencies caused by automated analyses, I use the second technique – formal specification of analysis contracts (see below). Finally, to detect complex inconsistencies that span several models, I develop the third technique – the integration property language (IPL), which engineers can use to specify assumptions, guarantees, and consistency statements over heterogeneous models and views.
More CPS research from my CMU group can be found here.
Model-Based Adaptation for Robotic Systems
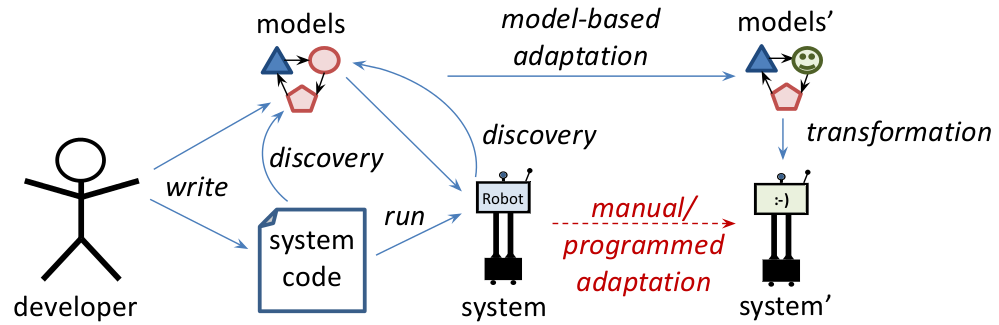
Mobile robots can accomplish increasingly impressive feats, but don’t stay deployed for long periods of time. As years pass, the technology becomes too complex and expensive to maintain and evolve, and is declared obsolete. The underlying problem is the low level of abstraction at which robotics code is written, making code difficult to evolve. Local fixes in the code enable low-level adaptation, they but make the code even more brittle to larger-scale changes.
This Model-Based Adaptation for Robotic Systems (MARS) project aims to raise the level of abstraction at which we adapt robotic systems. To this end, we apply a coordinated set of models to automate adaptation, which includes changing sensors, actuators, and software components. As the image above suggests, this model-based adaptation is more manageable, automated, and efficient than manual adaptation of code. The project is carried out based on the TurtleBot open-source robotic platform.
My role in this project is to build physical models (such as ones for power and motion) for Turtlebot and envision adaptation based on them. Since we use multiple models for adaptation, MARS is also a fitting context to apply my model integration techniques.
We reflected on challenges in physical modeling in this paper.
A couple of TurtleBot power data collection videos are available here and here.
Analysis Contracts for Cyber-Physical Systems
Designing a high-quality cyber-physical system, like an autonomous car, requires combined engineering for its cyber and physical aspects: control stability, planning, schedulability, protocol correctness, thermal safety, and energy efficiency — to name a few. Development of these aspects relies upon various domains of engineering expertise for appropriate system models and analytic operations on these models. For example, signal-flow graphs and simulation (e.g., in Simulink) are appropriate to analyze a controller’s stability, while state machines and reachability analysis can be used to ensure protocol correctness.
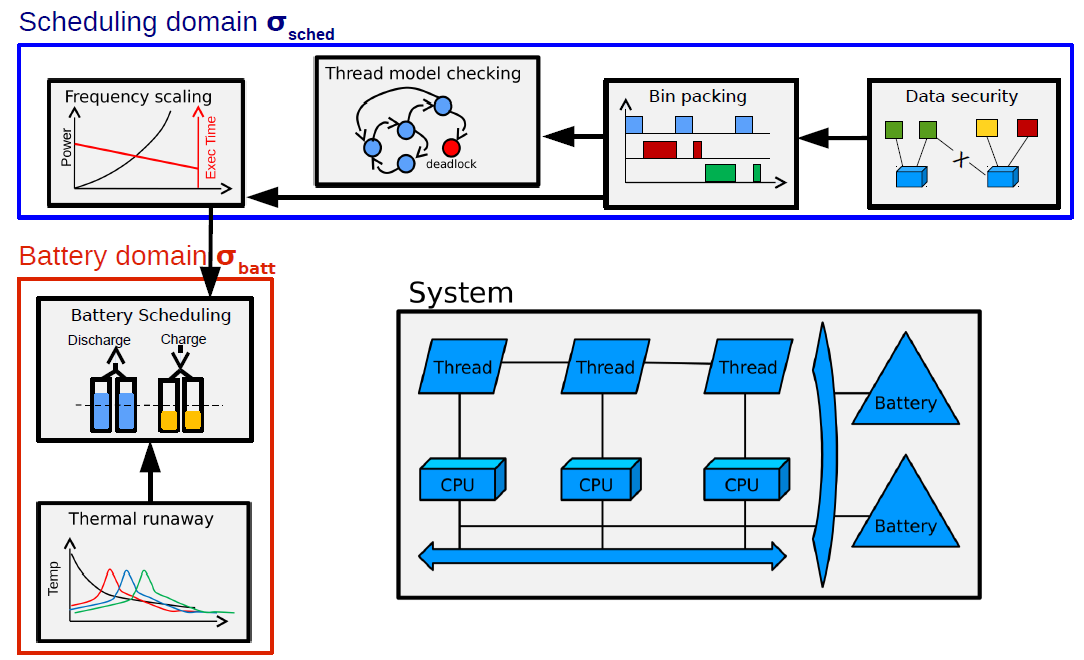
Analyses from different domains may deliver unsound results if their often-implicit assumptions are compromised. Such assumptions may concern complicated behaviors: for instance, the bin packing algorithm for thread-to-processor allocation is only applicable if the scheduling policy is equivalent to deadline-monotonic. So a major research question of multi-model CPS design is, how can we specify and verify correctness of co-operative multi-domain analyses in practice?
I developed a methodology to combine analyses based on analysis contracts. These contracts describe data inputs and outputs of each analysis, as well as its assumptions and guarantees. Using this specification, we can algorithmically verify correctness of analysis application using domain-specific models and verification techniques. The image above shows an example set of analyses for two domains: thread scheduling and design battery. The analysis contracts methodology is embodied in a tool called ACTIVE (Analysis Contract Integration Verifier) that builds upon the OSATE2 environment for AADL.
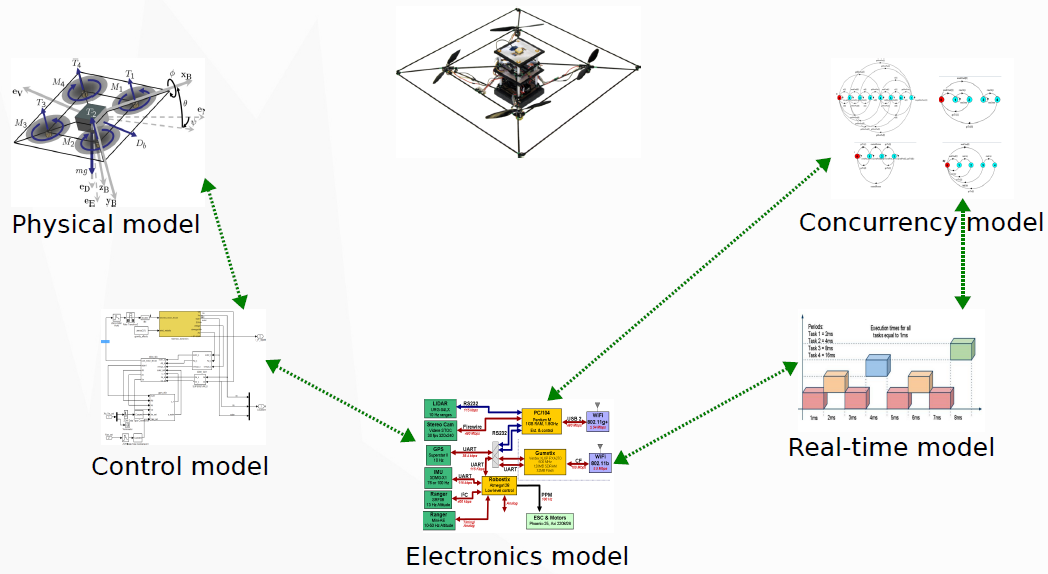
A cyber-physical system is a complex structure of its software, hardware, and physical elements, including their connections, relations, and properties. Representation and analysis of all these elements is carried out with models of different kind. An example of such a system (a quadrotor) and its models are shown in the image to the right. In CPS, a set of differential equations may describe the behavior of a physical system; a Simulink model may describe the controller; and a finite state machine may model software processes.
One obstacle to sound and efficient design and verification of CPS is the profound heterogeneity of models: their notions of computation, time, and state may be very different. This situation brings about the problem of consistency: how can we demonstrate that models do not have conflicting assumptions about the system structure and behavior? Is it possible to compose a correct system from heterogeneous models? How to avoid the communication breakdowns between the designers of different models?
My research focuses on creating a CPS multi-view framework that facilitates creating and maintaining inter-model relationships. I use architectural views to abstract crucial aspects of models and relate them to each other. Given this connection, we create algorithms to check and repair consistency of models via consistency of each model’s view.
Learn more:
Take a look at chapters 2, 4, and 6 of my PhD thesis.
For a summary of our approach to CPS model consistency, see this paper.
Many professionals in different application domains (neuroscience, social analysis, healthcare, or physics) are not satisfied with immutable software solutions and need to reach their goals by composing domain-specific components in far from trivial ways. An idea emerged recently that such people’s activities are similar to the ones of software architects and, hence, can be helped through formal architectural models and analysis. We termed this approach End-User Architecting.
Ozone Widget Framework (OWF) is one of many examples of systems that support creation of end-user compositions. Users are given a web dashboard on which they set up widgets into arbitrary compositions. This allows an expert to set up a rich computational system (composition) from dozens of reusable components without detailed technical knowledge or programming skills. Currently, OWF is used in spatial intelligence analysis.
I modeled OWF end-user compositions in an architectural style and described possible formal analyses for it. First of all, it is an important case study to investigate how an event-based style works for end-users because previous work concentrated on the data-flow architectural style (SORASCS Project). Also, formalized analysis of an architectural model can provide end users with needed functionality and, potentially, be carried over to any other system with the same style of compositions. Finally, Ozone’s compositions are special: initially, any communication between widgets is possible, and users need to “carve” their desired composition from a vast space of possible interactions. This is the opposite to the classic composition approach whereby users have to somehow declare every communication that will happen. See the tech report for details.
Learn more:
Our vision for end-user architecting is communicated in this paper.
For a less formal description check out this post.
To follow end-user architecting in more detail, visit Vishal’s page.
Management of Software Product Lines
Recent software engineering research proposes the software product line (SPL) methodology to develop series of systems with similar goals with a reusable set of assets. A concrete product can often be built automatically by just selecting the features that should go into this product. SPLs are known to achieve remarkable time and effort savings via disciplined reuse of core assets, e.g., requirements, plans, source code, or test cases, across multiple projects.
I interned at NASA Jet Propulsion Laboratory, working with the Multimission Ground System and Services Office to improve their product line of ground systems. The product line, called Advanced Multi-Mission Operations System (AMMOS), was developed from the early 1990s to support multiple ground data systems for deep-space NASA missions. My goal was to identify how AMMOS can improve the reuse process by taking modern SPL guidance into consideration. I identified gaps between the current practices of AMMOS and the state-of-the-art SPL approaches, and suggested two major improvement opportunities. First, a more comprehensive core asset documentation approach should augment large-scale reuse of existing artifacts in future missions. Second, explicit and rich specification of adaptation points (i. e., concrete changeable parts) of the AMMOS software should make ground systems development more predictable and cost-effective.
Single-Window Integrated Development Environment
During my time as a student of Lomonosov Moscow State University (MSU), I conducted research on how reduce numerous tool view-based user interfaces of integrated development environments (IDEs). For example, Eclipse and Visual Studio have dozens of tool views, which distract programmers who have to open, resize, move, and close them. The reason for this proliferation of tool views is the plugin-based architecture: it makes creation of new tool views very easy; however, it’s difficult to ensure usability and consistency across all tool views. In other words, the extensible technical architecture of an IDE is at odds with usability of user interfaces for IDEs.
Our idea was to replace the functionality of most used tool views with few reusable user interface mechanisms and, hence, alleviate the problem. The mechanisms were: a breadcrumbs bar that provided interfaces for plugins to put custom information there, in-text widgets for compilation errors and debugging messages, and a rich status bar as a home for status-related information from plugins. Our further study showed that this approach is useful: the most common tool views can be replaced, and developers adopt new interface tools for their routine tasks.